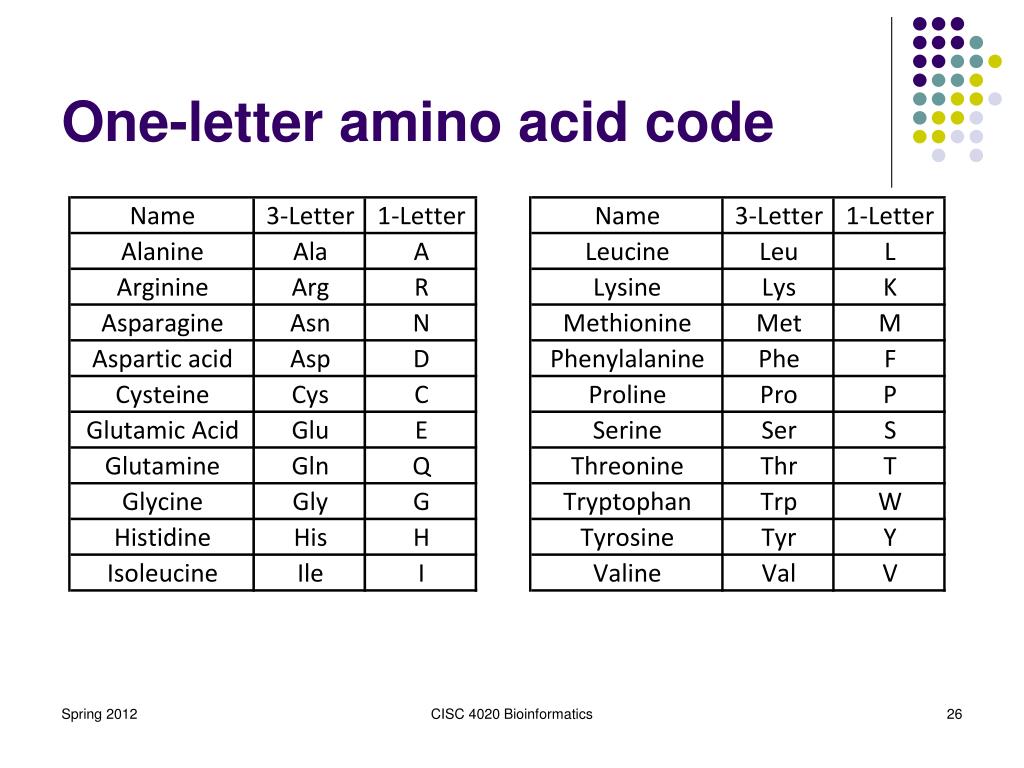
Amino Acid 1 Letter Code
Die Welt der Proteine ist komplex und vielfältig. Um diese Komplexität zu bewältigen, nutzen Biochemiker und Molekularbiologen verschiedene Kurzschreibweisen, um Aminosäuren, die Bausteine der Proteine, darzustellen. Eine besonders prägnante und weit verbreitete Methode ist der Ein-Buchstaben-Code für Aminosäuren. Dieser Code ermöglicht es, Proteinsequenzen kompakt und effizient darzustellen, was besonders in der Bioinformatik und bei der Analyse großer Datensätze von unschätzbarem Wert ist.
Warum ein Ein-Buchstaben-Code?
Die traditionelle Drei-Buchstaben-Abkürzung (z.B. Ala für Alanin) ist zwar intuitiv, aber für lange Proteinsequenzen unhandlich. Stellen Sie sich vor, Sie müssen eine Sequenz mit Hunderten oder Tausenden von Aminosäuren manuell eingeben oder vergleichen. Der Ein-Buchstaben-Code reduziert diesen Aufwand erheblich und minimiert das Risiko von Tippfehlern. Er ist besonders nützlich in:
- Datenbanken: Proteinsequenzdatenbanken wie UniProt verwenden den Ein-Buchstaben-Code, um Speicherplatz zu sparen und Suchvorgänge zu beschleunigen.
- Sequence Alignment: Algorithmen für Sequence Alignments, die Ähnlichkeiten zwischen Proteinsequenzen finden, arbeiten effizienter mit dem Ein-Buchstaben-Code.
- Visualisierung von Proteinmodellen: Software zur Darstellung von Proteinstrukturen kann den Ein-Buchstaben-Code verwenden, um Aminosäuren an bestimmten Positionen hervorzuheben.
- Publikationen: In wissenschaftlichen Veröffentlichungen werden lange Peptidsequenzen oft im Ein-Buchstaben-Code dargestellt, um Platz zu sparen und die Lesbarkeit zu erhöhen.
Kompaktheit und Effizienz
Der Hauptvorteil des Ein-Buchstaben-Codes ist seine Kompaktheit. Eine lange Proteinsequenz kann als eine einzige Zeichenkette dargestellt werden, was die Analyse und Verarbeitung erheblich vereinfacht. Dies ist besonders wichtig in der Genomforschung und Proteomik, wo riesige Datenmengen analysiert werden müssen.
Minimierung von Fehlern
Die Verwendung eines einzelnen Buchstabens reduziert die Wahrscheinlichkeit von Tippfehlern im Vergleich zur Drei-Buchstaben-Abkürzung. Dies ist entscheidend für die Genauigkeit von wissenschaftlichen Daten.
Die Zuordnung der Buchstaben zu den Aminosäuren
Die Zuordnung der Buchstaben zu den Aminosäuren ist weitgehend intuitiv, aber es gibt einige Ausnahmen, die auf den ersten Blick verwirrend erscheinen können. Die meisten Aminosäuren werden durch den ersten Buchstaben ihres Namens repräsentiert:
- A für Alanin
- C für Cystein
- D für Asparaginsäure
- G für Glycin
- H für Histidin
- I für Isoleucin
- L für Leucin
- M für Methionin
- P für Prolin
- S für Serin
- T für Threonin
- V für Valin
Problematisch wird es, wenn mehrere Aminosäuren mit demselben Buchstaben beginnen. In diesen Fällen wurden andere Buchstaben basierend auf Häufigkeit, Ähnlichkeit oder anderen Kriterien gewählt:
- F für Phenylalanin (da P bereits für Prolin verwendet wird)
- E für Glutaminsäure (da G bereits für Glycin verwendet wird und E phonetisch ähnlich ist)
- K für Lysin (kommt vom deutschen Wort "Lysin")
- N für Asparagin (ähnlich Asparaginsäure (D))
- Q für Glutamin (ähnlich Glutaminsäure (E))
- R für Arginin (ähnlich dem ersten Buchstaben, aber bereits vergeben)
- W für Tryptophan (Doppelbindung im Ring, ähnelt im Aufbau)
- Y für Tyrosin (Y ähnelt der Struktur des Tyrosins)
Die Sonderfälle: B, Z und X
Zusätzlich zu den 20 proteinogenen Aminosäuren gibt es drei Sonderzeichen:
- B für Asparagin oder Asparaginsäure (Asx): Wird verwendet, wenn nicht eindeutig bestimmt werden kann, ob es sich um Asparagin oder Asparaginsäure handelt.
- Z für Glutamin oder Glutaminsäure (Glx): Wird verwendet, wenn nicht eindeutig bestimmt werden kann, ob es sich um Glutamin oder Glutaminsäure handelt.
- X für eine unbekannte oder nicht-standardmäßige Aminosäure: Wird verwendet, wenn die Aminosäure an dieser Position nicht identifiziert werden konnte.
Real-World Beispiele und Daten
Betrachten wir ein kurzes Peptid: Alanin-Glycin-Serin-Threonin-Lysin.
- Im Drei-Buchstaben-Code: Ala-Gly-Ser-Thr-Lys
- Im Ein-Buchstaben-Code: AGSTK
Der Ein-Buchstaben-Code ist offensichtlich kürzer und leichter zu lesen, besonders bei längeren Sequenzen. In der UniProt Datenbank, der umfassendsten Ressource für Proteinsequenz- und Funktionsinformationen, werden alle Sequenzen im Ein-Buchstaben-Code gespeichert und angezeigt.
Ein weiteres Beispiel: Die Sequenz des Insulin A-Kette (vereinfacht) im Ein-Buchstaben-Code ist: GIVEQCCTSICSLYQLENYCN.
Diese Sequenz wäre im Drei-Buchstaben-Code deutlich länger und weniger übersichtlich. Algorithmen für die multiple Sequenzausrichtung, wie CLUSTAL Omega, nutzen den Ein-Buchstaben-Code, um große Mengen an Proteinsequenzen effizient zu verarbeiten und Homologien zwischen den Sequenzen zu identifizieren.
Diese Analysen sind entscheidend für das Verständnis der Evolution von Proteinen und die Identifizierung von konservierten Domänen, die für die Funktion des Proteins wichtig sind.
Herausforderungen und Einschränkungen
Obwohl der Ein-Buchstaben-Code sehr nützlich ist, gibt es auch einige Herausforderungen und Einschränkungen:
- Lernkurve: Es erfordert ein gewisses Maß an Auswendiglernen, um die Zuordnung der Buchstaben zu den Aminosäuren zu beherrschen.
- Mehrdeutigkeit: Die Sonderzeichen B, Z und X können zu Mehrdeutigkeiten führen, wenn die genaue Aminosäure an einer bestimmten Position unbekannt ist.
- Nicht-proteinogene Aminosäuren: Der Standard-Ein-Buchstaben-Code deckt nur die 20 proteinogenen Aminosäuren ab. Für nicht-proteinogene Aminosäuren, die in einigen Proteinen vorkommen, sind zusätzliche Symbole oder Modifikationen erforderlich.
Fazit
Der Ein-Buchstaben-Code für Aminosäuren ist ein unverzichtbares Werkzeug in der modernen Biochemie, Molekularbiologie und Bioinformatik. Seine Kompaktheit, Effizienz und die Minimierung von Fehlern machen ihn zu einem Standard für die Darstellung und Analyse von Proteinsequenzen. Obwohl es einige Herausforderungen gibt, überwiegen die Vorteile bei weitem die Nachteile.
Empfehlung: Machen Sie sich mit dem Ein-Buchstaben-Code vertraut, wenn Sie in den Bereichen Biochemie, Molekularbiologie oder Bioinformatik arbeiten. Es wird Ihnen helfen, Proteinsequenzen effizienter zu lesen, zu verstehen und zu analysieren. Nutzen Sie Online-Ressourcen und Tools, um den Code zu üben und zu verinnerlichen. Die Fähigkeit, den Ein-Buchstaben-Code fließend zu beherrschen, ist eine wertvolle Fähigkeit für jeden, der sich mit Proteinen beschäftigt.


.PNG)
