Amino Acid Single Letter Code
Der Aminosäure-Einbuchstabencode ist ein System zur Darstellung jeder der 20 gebräuchlichsten Aminosäuren mit einem einzigen Buchstaben des Alphabets. Er dient als Kurzform für die längeren, dreibuchstabigen Abkürzungen oder die vollständigen Namen der Aminosäuren.
Dieser Code ist besonders nützlich, um lange Proteinsequenzen prägnant darzustellen. Die Sequenzen sind die Reihenfolge der Aminosäuren in einem Protein. Die Verwendung von Einzelbuchstaben spart Platz und macht die Analyse und den Vergleich von Proteinsequenzen einfacher.
Hier ist eine schrittweise Erklärung, wie der Aminosäure-Einbuchstabencode funktioniert:
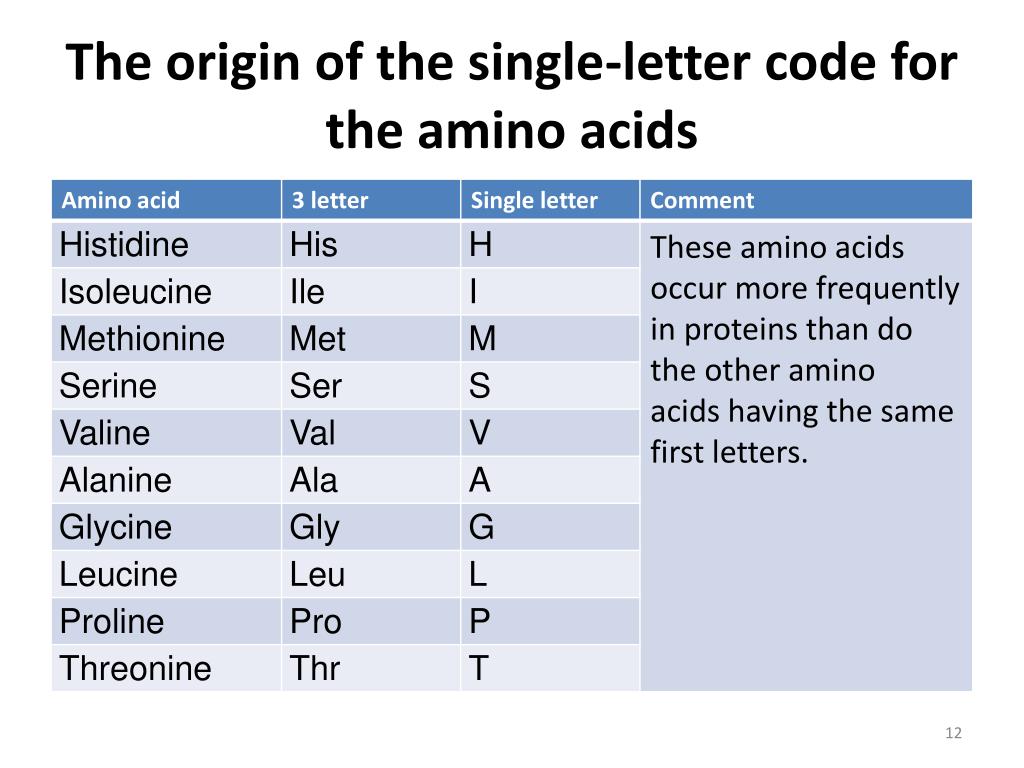
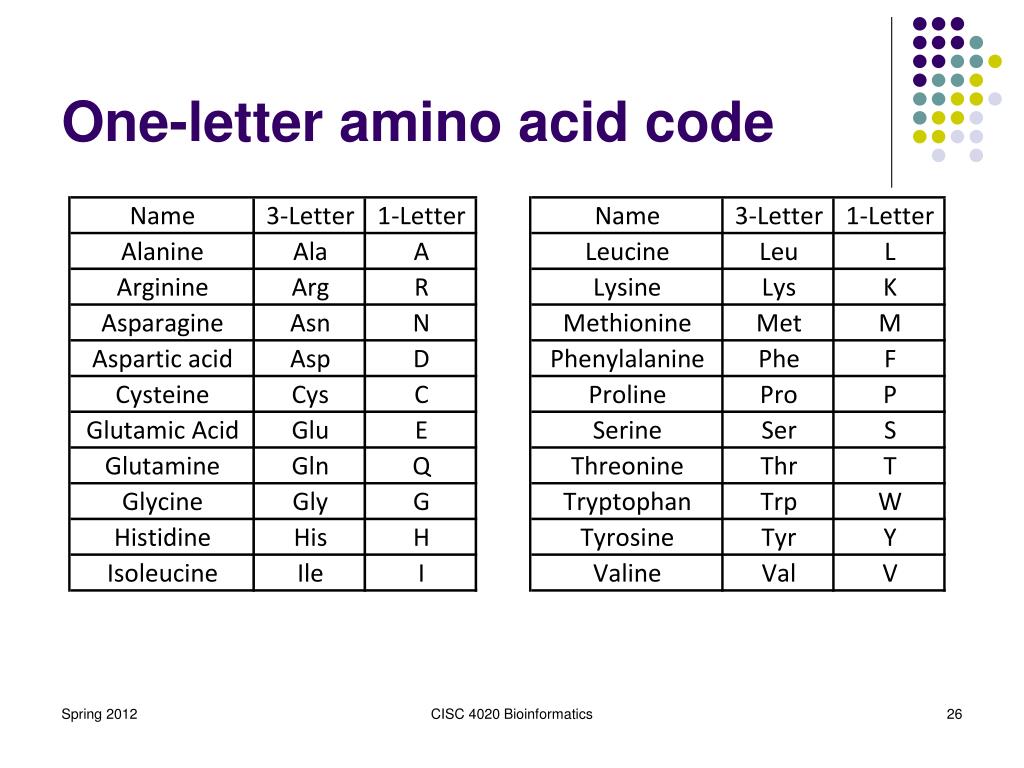
Schritt 1: Die 20 Aminosäuren kennen. Es gibt 20 Aminosäuren, die üblicherweise in Proteinen vorkommen. Jede Aminosäure hat einen Namen, eine dreibuchstabige Abkürzung und einen einbuchstabigen Code. Es ist wichtig, diese Aminosäuren zu identifizieren, bevor Sie zum nächsten Schritt übergehen.
Schritt 2: Die häufigsten Zuordnungen verstehen. Einige Einbuchstabencodes sind intuitiv. Beispielsweise steht 'A' für Alanin, 'C' für Cystein, 'H' für Histidin und 'I' für Isoleucin. Diese Codes basieren auf dem ersten Buchstaben des Namens der Aminosäure. Merken Sie sich diese einfach zuzuordnenden Codes zuerst. Zum Beispiel:
A = Alanin
C = Cystein
H = Histidin
I = Isoleucin
Schritt 3: Codes mit Konflikten lernen. Manche Aminosäuren teilen sich den gleichen Anfangsbuchstaben. In diesen Fällen werden andere Buchstaben verwendet, oft solche, die im Namen der Aminosäure vorkommen oder klanglich ähnlich sind. Ein Beispiel hierfür ist Asparagin (N) und Asparaginsäure (D). Hier sind einige Beispiele für diese nicht-intuitiven Zuordnungen. Die Logik dahinter muss man sich oft merken:
F = Phenylalanin (Da 'P' für Prolin steht)
K = Lysin (Von einem alternativen Namen, "Lysin")
N = Asparagin (Da 'A' bereits für Alanin verwendet wird)
D = Asparaginsäure (Da 'A' bereits für Alanin verwendet wird)
Schritt 4: Die weniger intuitiven Codes auswendig lernen. Einige Codes erfordern einfach Auswendiglernen, da sie nicht direkt vom Namen der Aminosäure abgeleitet sind. Dies erfordert Übung und Wiederholung. Hier sind einige Beispiele:
W = Tryptophan (Doppelringstruktur ähnlich zwei "V")
Y = Tyrosin (Ähnlichkeit mit Phenylalanin, daher das nächste verfügbare)
Q = Glutamin (Folgt auf Glutaminsäure (E) im Alphabet)
Schritt 5: Üben Sie die Umwandlung von Sequenzen. Nehmen Sie eine Proteinsequenz in vollständiger Namens- oder Dreibuchstabenform und wandeln Sie sie in den Einbuchstabencode um. Dies hilft, das Verständnis zu festigen. Zum Beispiel:
Die Sequenz Alanin-Glycin-Cystein-Tyrosin wird zu AGCY.
Die Sequenz Asparaginsäure-Glutamin-Lysin-Leucin wird zu DQLK.
Praktische Anwendungen: Der Aminosäure-Einbuchstabencode ist unverzichtbar in der Bioinformatik. Er wird verwendet, um riesige Datenbanken von Proteinsequenzen zu durchsuchen und zu vergleichen. Dies hilft bei der Identifizierung verwandter Proteine und der Vorhersage ihrer Funktionen. Darüber hinaus wird er in Publikationen und wissenschaftlichen Arbeiten verwendet, um Proteinsequenzen prägnant darzustellen, was die Kommunikation und das Verständnis erleichtert.