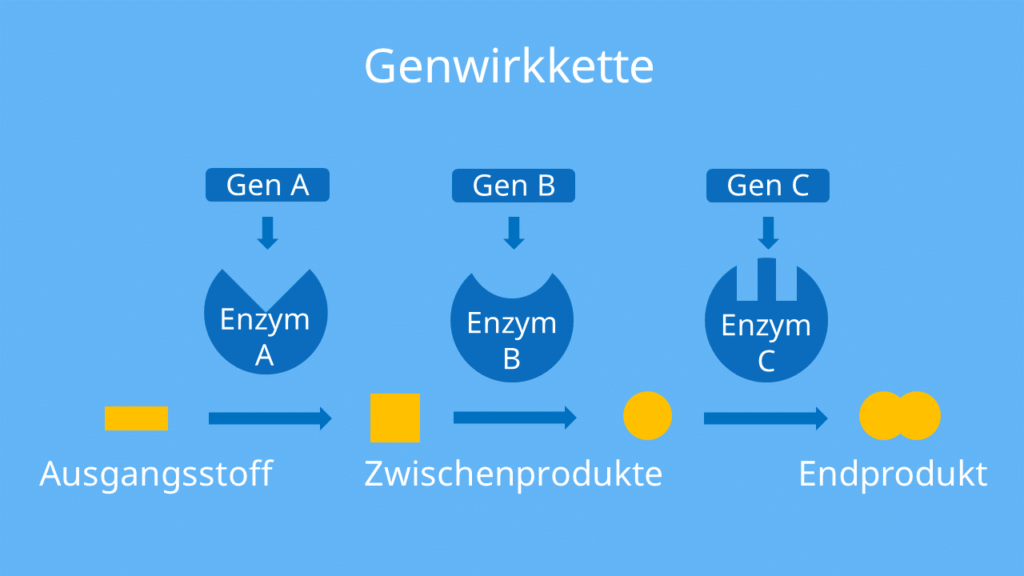
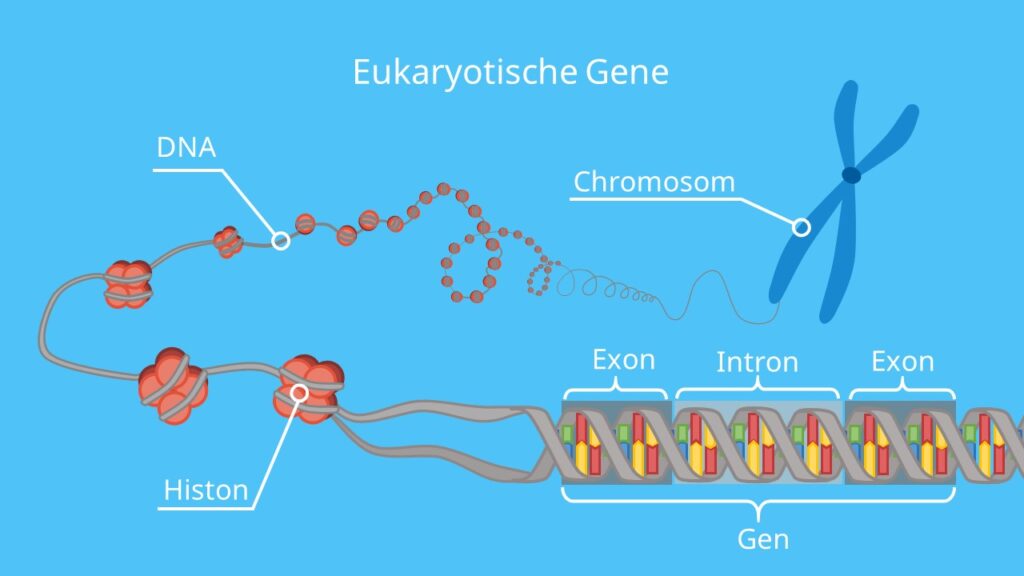
Ein Gen Ein Polypeptid Hypothese

Hast du dich jemals gefragt, wie unsere Gene, diese winzigen Abschnitte unserer DNA, letztendlich dazu führen, dass wir so aussehen und funktionieren, wie wir es tun? Es ist ein faszinierendes Rätsel, das Wissenschaftler über Jahrzehnte hinweg gelöst haben. Und ein wichtiger Schlüssel zu diesem Verständnis ist die "Ein-Gen-Ein-Polypeptid-Hypothese". Vielleicht klingt das kompliziert, aber keine Sorge – wir werden es gemeinsam aufschlüsseln!
Viele Studierende kämpfen mit der Molekularbiologie, insbesondere mit dem Zusammenhang zwischen Genen und Proteinen. Die "Ein-Gen-Ein-Polypeptid-Hypothese" ist ein Eckpfeiler dieses Verständnisses. Wir werden uns Schritt für Schritt durch die Grundlagen arbeiten, mit klaren Erklärungen und praktischen Beispielen.
Was ist ein Gen?
Beginnen wir mit den Grundlagen. Ein Gen ist ein Abschnitt der DNA, der die Anweisungen zur Herstellung eines bestimmten Produkts enthält. Stell dir die DNA als ein riesiges Kochbuch vor, und jedes Gen ist ein einzelnes Rezept. Diese Rezepte enthalten die Informationen, die unsere Zellen benötigen, um alles herzustellen, von Enzymen, die chemische Reaktionen beschleunigen, bis hin zu Strukturproteinen, die unsere Zellen formen.
Gene sind nicht einfach nur Bauanleitungen, sie sind auch sehr spezifisch. Jedes Gen enthält einen Code, der festlegt, welche Aminosäuren in welcher Reihenfolge miteinander verbunden werden müssen, um ein bestimmtes Protein zu bilden. Aber bevor wir uns den Proteinen zuwenden, müssen wir verstehen, was ein Polypeptid ist.
Was ist ein Polypeptid?
Ein Polypeptid ist eine Kette von Aminosäuren, die durch Peptidbindungen miteinander verbunden sind. Aminosäuren sind die Bausteine von Proteinen. Stell dir ein Polypeptid wie eine Perlenkette vor, wobei jede Perle eine Aminosäure ist. Die Reihenfolge der Perlen (Aminosäuren) bestimmt die einzigartige Form und Funktion der Kette. Ein Polypeptid ist kein fertiges Protein, sondern eher eine Vorstufe.
Es ist wichtig zu verstehen, dass ein Protein aus einem oder mehreren Polypeptiden bestehen kann. Einige Proteine bestehen aus einer einzigen Polypeptidkette, während andere aus mehreren Polypeptidketten bestehen, die miteinander interagieren und eine komplexe dreidimensionale Struktur bilden.
Die Ein-Gen-Ein-Polypeptid-Hypothese: Der Kern der Sache
Nun kommen wir zum Kernpunkt: Die Ein-Gen-Ein-Polypeptid-Hypothese besagt, dass jedes Gen die Information zur Herstellung eines einzigen Polypeptids enthält. In anderen Worten, jedes Gen codiert für ein spezifisches Polypeptid. Dieses Polypeptid kann dann entweder ein eigenständiges Protein sein, oder sich mit anderen Polypeptiden zusammenlagern, um ein funktionelles Protein zu bilden.
Es ist wichtig zu beachten, dass diese Hypothese eine Weiterentwicklung der ursprünglichen "Ein-Gen-Ein-Enzym-Hypothese" ist, die von George Beadle und Edward Tatum in den 1940er Jahren aufgestellt wurde. Ihre bahnbrechenden Experimente mit dem Schimmelpilz Neurospora crassa zeigten, dass bestimmte Mutationen in Genen zu Defekten in spezifischen Enzymen führten. Ihre Forschung legte den Grundstein für das Verständnis der Verbindung zwischen Genen und Proteinen.
Die "Ein-Gen-Ein-Enzym-Hypothese" wurde später zur "Ein-Gen-Ein-Polypeptid-Hypothese" erweitert, da man erkannte, dass nicht alle Proteine Enzyme sind und dass einige Proteine aus mehreren Polypeptiden bestehen, die von verschiedenen Genen codiert werden.
Wie funktioniert das in der Praxis?
Denken wir an ein einfaches Beispiel: Das Gen für Insulin. Insulin ist ein Hormon, das den Blutzuckerspiegel reguliert. Das Insulin-Gen enthält die DNA-Sequenz, die die Anweisungen zur Herstellung des Insulin-Polypeptids liefert. Dieses Polypeptid wird dann weiterverarbeitet, um das funktionelle Insulin-Protein zu bilden. Ohne das intakte Insulin-Gen kann der Körper kein funktionelles Insulin produzieren, was zu Diabetes führen kann.
Ein anderes Beispiel ist Hämoglobin, das Protein in roten Blutkörperchen, das Sauerstoff transportiert. Hämoglobin besteht aus vier Polypeptidketten: zwei Alpha-Globin-Ketten und zwei Beta-Globin-Ketten. Jede Kette wird von einem separaten Gen codiert. Mutationen in einem dieser Gene können zu verschiedenen Formen von Anämie führen, wie z.B. der Sichelzellenanämie.
Von der DNA zum Polypeptid: Der Prozess
Der Prozess, bei dem die Information in einem Gen in ein Polypeptid umgewandelt wird, ist ein zweistufiger Prozess, der als Gentranskription und Translation bezeichnet wird.
1. Transkription: In diesem Schritt wird die DNA-Sequenz des Gens in eine komplementäre RNA-Sequenz, die sogenannte messenger RNA (mRNA), umgeschrieben. Stell dir vor, du kopierst ein Rezept aus dem Kochbuch (DNA) auf eine Notizkarte (mRNA). Die mRNA dient als mobile Kopie der genetischen Information, die aus dem Zellkern zu den Ribosomen transportiert werden kann.
2. Translation: In diesem Schritt wird die mRNA-Sequenz von den Ribosomen "gelesen", und die entsprechende Aminosäuresequenz wird synthetisiert. Die Ribosomen fungieren als die "Köche", die das Rezept (mRNA) verwenden, um das Polypeptid (das Gericht) herzustellen. Transfer-RNA (tRNA) Moleküle bringen die richtigen Aminosäuren zu den Ribosomen, entsprechend den Codons (Dreiergruppen von Nukleotiden) auf der mRNA. Jedes Codon entspricht einer bestimmten Aminosäure. Dieser Prozess setzt sich fort, bis das gesamte Polypeptid synthetisiert ist.
Ausnahmen und Komplexitäten
Obwohl die Ein-Gen-Ein-Polypeptid-Hypothese ein grundlegendes Konzept ist, gibt es einige Ausnahmen und Komplexitäten, die es wert sind, erwähnt zu werden:
- Alternative Spleißung: Ein einziges Gen kann durch alternatives Spleißen mehrere verschiedene mRNA-Moleküle erzeugen. Dies bedeutet, dass aus einem einzigen Gen verschiedene Polypeptide entstehen können.
- Nicht-codierende RNAs: Nicht alle Gene codieren für Polypeptide. Einige Gene codieren für nicht-codierende RNAs (ncRNAs), wie z.B. tRNA, rRNA und microRNA, die wichtige regulatorische Funktionen in der Zelle haben.
- Proteinmodifikationen: Nach der Translation können Polypeptide durch verschiedene posttranslationale Modifikationen verändert werden, wie z.B. die Hinzufügung von Zuckern (Glykosylierung) oder Phosphaten (Phosphorylierung). Diese Modifikationen können die Aktivität, Lokalisation und Interaktionen des Proteins beeinflussen.
Trotz dieser Komplexitäten bleibt die Ein-Gen-Ein-Polypeptid-Hypothese ein wichtiges Rahmenwerk für das Verständnis der Beziehung zwischen Genen und Proteinen.
Warum ist das wichtig?
Das Verständnis der Ein-Gen-Ein-Polypeptid-Hypothese ist aus mehreren Gründen wichtig:
- Genetische Krankheiten: Viele genetische Krankheiten werden durch Mutationen in Genen verursacht, die für wichtige Proteine codieren. Das Verständnis, wie diese Mutationen die Funktion der Proteine beeinflussen, kann zu neuen Therapien und Behandlungen führen.
- Drug Development: Viele Medikamente wirken, indem sie an spezifische Proteine binden und deren Aktivität beeinflussen. Das Verständnis der Struktur und Funktion von Proteinen ist entscheidend für die Entwicklung neuer und wirksamerer Medikamente.
- Evolution: Die Ein-Gen-Ein-Polypeptid-Hypothese hilft uns zu verstehen, wie sich die genetische Information im Laufe der Zeit verändert und wie diese Veränderungen zu neuen Merkmalen und Anpassungen führen.
- Personalisierte Medizin: Mit dem Aufkommen der Genomsequenzierung wird es zunehmend möglich, die genetische Veranlagung eines Individuums für bestimmte Krankheiten zu bestimmen und Behandlungen entsprechend anzupassen.
Praktische Anwendung: Dein eigenes Gen-Polypeptid-Modell
Um das Konzept der Ein-Gen-Ein-Polypeptid-Hypothese besser zu veranschaulichen, kannst du dein eigenes Modell erstellen. Du benötigst:
- Verschiedenfarbige Perlen (jede Farbe repräsentiert eine andere Aminosäure).
- Einen Faden oder eine Schnur.
- Papier und Stifte.
Schritt 1: Wähle ein Gen aus. Du kannst ein einfaches Beispiel wie das Gen für eine bestimmte Haarfarbe oder ein komplexeres Gen wie das für Insulin verwenden.
Schritt 2: Finde die Aminosäuresequenz des Polypeptids, das von diesem Gen codiert wird. Diese Information findest du in Online-Protein-Datenbanken wie UniProt.
Schritt 3: Ordne jeder Aminosäure eine Farbe zu. Zum Beispiel könnte Alanin rot, Glycin blau und Valin grün sein.
Schritt 4: Fädele die Perlen entsprechend der Aminosäuresequenz des Polypeptids auf den Faden. Du hast jetzt ein physisches Modell des Polypeptids, das von deinem gewählten Gen codiert wird!
Schritt 5: Beschrifte dein Modell und erkläre, wie das Gen die Anweisungen zur Herstellung dieses Polypeptids liefert. Du kannst auch die Auswirkungen von Mutationen in dem Gen auf die Struktur und Funktion des Polypeptids erklären.
Zusammenfassung
Die Ein-Gen-Ein-Polypeptid-Hypothese ist ein grundlegendes Konzept in der Molekularbiologie, das die Verbindung zwischen Genen und Proteinen erklärt. Obwohl es Ausnahmen und Komplexitäten gibt, bleibt es ein wichtiges Rahmenwerk für das Verständnis, wie unsere Gene unsere Merkmale und Funktionen bestimmen. Indem wir die Ein-Gen-Ein-Polypeptid-Hypothese verstehen, können wir die genetischen Grundlagen von Krankheiten besser verstehen, neue Therapien entwickeln und die Evolution des Lebens auf der Erde erforschen.
Ich hoffe, dieser Artikel hat dir geholfen, die Ein-Gen-Ein-Polypeptid-Hypothese besser zu verstehen. Bleib neugierig und forsche weiter!